Learn about Mean Time to Recovery, including how to measure it, and leverage it in dashboards and visualizations with Metabase.
Mean time to recovery, or MTTR, is the average time it takes to recover from a partial or total failure. This metric is used specifically for DevOps, giving insight into team stability and flow. MTTR covers the entire process of recovering from a failure from start to finish, with the “finish” meaning the service is fully operational again. Using MTTR is also an excellent way to compare how well your recovery times are against your competitors. While figuring out your MTTR doesn’t fully address everything happening when a failure occurs, it’s excellent for having a record of the speed your team addresses a failure and how much time the overall recovery process takes.
Get Started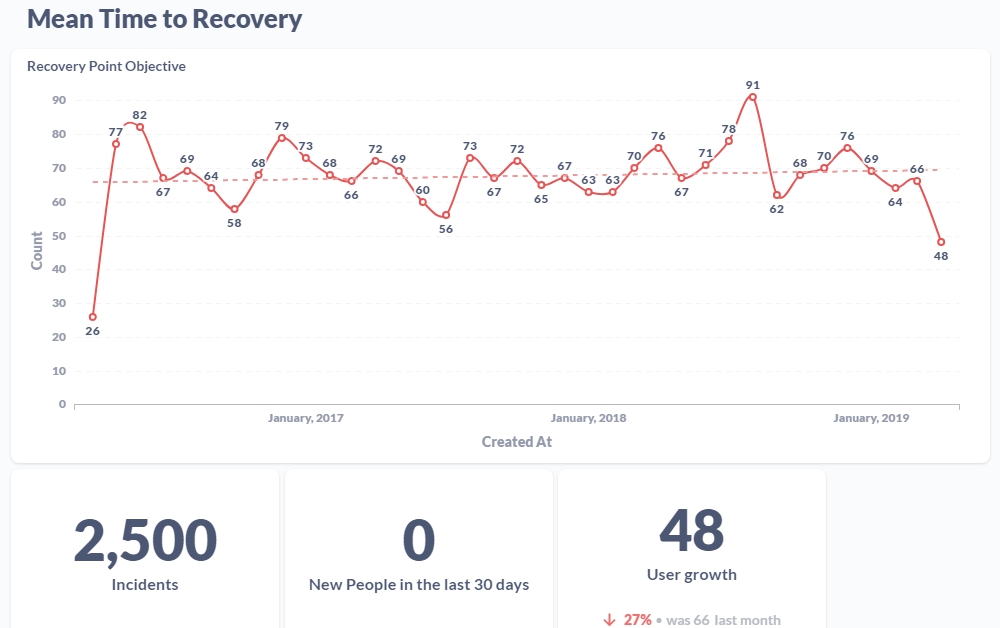
You’ll need to know the total downtime for every incident within a set period of time, like the average for a day, week, month, and so on. Then, you’ll take the total number of incidents that occurred in that timeframe. You’re going to divide the total number of minutes down by the number of incidents that occurred during the specified period of time. For example, if your service was down for a total of 2 hours (120 minutes) in a week and there were 3 separate incidents total, you would divide 120 by 3. Your mean time to recovery would then be 40 minutes.
Get everyone on the same page by collecting your most important metrics into a single view.
Take your data wherever it needs to go by embedding it in your internal wikis, websites, and content.
Empower your team to measure their own progress and explore new paths to achieve their goals.

That's right, no sales calls necessary—just sign up, and get running in under 5 minutes.

We connect to the most popular production databases and data warehouses.
Invite your team and start building dashboards—no SQL required.



